就來搞懂 K8s Leader Election 吧
一個分散式鎖的解法, 使用 K8s Leader Election
前因後果
安安, 由於工作上有遇到一個情境會需要使用到分散式鎖的概念進行解題,雖然最後不是透過這篇文章要說明的方法解決的,但我覺得這方法也蠻好玩的,所以寫篇文章來做個紀錄。
好,因為使用情境比較特殊,我們就先來定義一下這篇文章實做的情境吧!
情境: 當一個 method 作為專案被部屬至 K8s 環境中,replica 為 3,其中只能有一個 pod 執行該 method。
什麼是 Kubernetes Leader Election?
在分散式系統中,Leader Election 是一種協調機制,簡單來說就是讓多個服務副本(Pod)中,只有一個被選為 Leader 來執行特定的任務。這樣做可以防止重複工作、確保資料一致性,在需要協調多個服務副本的場景下非常重要。
在 Kubernetes 中,Leader Election 通常用於以下情況
以我目前工作上遇到的案例來說,有以下幾種:
- 當有多個 replica 時,可能只有一個 replica 被允許處理寫入請求
- 如果有一個每隔一段時間需要執行的任務,Leader Election 可以確保只有一個 Pod 執行該任務
Leader Election 的工作原理
Kubernetes 的 Leader Election 通常依賴於以下機制:
Coordination Resource (協調資源)
Leader Election 需要一個共享的資源來進行協調。在 Kubernetes 中,這通常是:
- ConfigMap:這是最常見的方式。會用一個特定的 ConfigMap 來儲存當前 Leader 的資訊(例如 Leader 的 ID、租約到期時間等)
- Lease (租約) 對象:coordination.k8s.io/v1 API 引入了 Lease 對象,它是專為 Leader Election 設計的,比 ConfigMap 效率更高,而且有內建的租約過期機制
- Endpoints:在早期版本中也曾被使用,但現在比較少見了
競爭和續約 (Contention and Renewal)
所有參與 Leader Election 的 Pod 都會嘗試獲取(或更新)這個協調資源,把自己標記為 Leader,成功獲取或更新資源的那個就成為 Leader。
另外,Leader 會定期「續約」(更新資源),來表明它還活著,仍然是 active 的 Leader。如果 Leader 沒能續約(比如因為程式異常或 IO 問題),租約就會過期,其他 Pod 就會開始競爭成為新的 Leader。
Client-go
Kubernetes 應用程式通常會使用 client-go 庫中提供的 Leader Election 相關工具,像是 leaderelection.LeaderElectionConfig 和 leaderelection.LeaderElector,來簡化 Leader Election 的實作。
實做部份:使用 Golang (引用 client-go 庫)
實作部份我會直接用程式碼來呈現,語言選擇 Golang(因為這是我最近私下在玩的語言),相關的 library 會使用 client-go。
這是官方提供的 library,覺得挺不錯的,特別是在開發 Kubernetes 相關應用程式時很好用。
引入必要的 library
import (
"context"
"flag"
"fmt"
"os"
"time"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/tools/leaderelection"
"k8s.io/client-go/tools/leaderelection/resourcelock"
"k8s.io/klog/v2"
)設定 Leader Election 相關參數
leaseLockName:用於 Leader Election 的 Lease 對象名稱leaseLockNamespace:Lease 對象所在的 namespaceid:當前參與者的唯一 ID,通常是 Pod 的名稱
var (
kubeconfig = flag.String("kubeconfig", "", "Path to a kubeconfig. Only required if out-of-cluster.")
leaseLockName = flag.String("lease-lock-name", "my-leader-election-lock", "the name of the lease lock resource")
leaseLockNamespace = flag.String("lease-lock-namespace", "default", "the namespace of the lease lock resource")
id = flag.String("id", "", "the id of this leader election participant")
)建立 Kubernetes client
func buildConfig(kubeconfig string) (*rest.Config, error) {
if kubeconfig != "" {
cfg, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
if err != nil {
return nil, err
}
return cfg, nil
}
cfg, err := rest.InClusterConfig()
if err != nil {
return nil, err
}
return cfg, nil
}啟動 Kubernet client
config, err := buildConfig(*kubeconfig)
if err != nil {
_ = fmt.Errorf("error building kubeconfig: %s", err.Error())
}
client := kubernetes.NewForConfigOrDie(config)設定 Leader Election 相關函數
這些函數定義了當 Pod 成為 Leader 或失去 Leader 權限時該做什麼事情。
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 這裡是當你成為 Leader 時要執行的主要邏輯
run := func(ctx context.Context) {
klog.Infof("%s: I am the leader! Performing my duties...", *id)
// 在這裡執行只有 Leader 才應該執行的業務邏輯
// 例如:啟動控制器、處理特定任務等
for {
select {
case <-ctx.Done():
klog.Infof("%s: Leader duties stopped.", *id)
return
case <-time.After(5 * time.Second):
klog.Infof("%s: Still the leader, doing important work...", *id)
}
}
}
// 建立 LeaderElectionConfig
lock := &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{
Name: *leaseLockName,
Namespace: *leaseLockNamespace,
},
Client: client.CoordinationV1(),
LockConfig: resourcelock.LockConfig{
Identity: *id,
},
}
leaderElectionConfig := leaderelection.LeaderElectionConfig{
Lock: lock,
// 這個 Pod 成為 Leader 後,執行 `run` 函數
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
run(ctx)
},
// 當 Pod 失去 Leader 身份時執行
OnStoppedLeading: func() {
klog.Infof("%s: Lost leadership, exiting.", *id)
cancel() // 終止上下文,退出程式
},
// 當有新的 Leader 被選出時執行
OnNewLeader: func(identity string) {
if identity == *id {
return
}
klog.Infof("%s: New leader elected: %s", *id, identity)
},
},
// 續約間隔:Leader 會每隔多久更新 Lease 資源
LeaseDuration: 15 * time.Second,
// 續約失敗後,多久會嘗試再次成為 Leader(非 Leader 才會競爭)
RenewDeadline: 10 * time.Second,
// 在失去領導權後,多久會釋放領導權
RetryPeriod: 2 * time.Second,
}啟動 Leader Election
leaderElector, err := leaderelection.NewLeaderElector(leaderElectionConfig)
if err != nil {
klog.Fatalf("Error creating leader elector: %s", err.Error())
}
leaderElector.Run(ctx) // 啟動 Leader Election 循環如何編譯和運行(在 Kubernetes 叢集外部進行測試)
編譯:
go build -o my-leader-app main.go運行(提供 kubeconfig):
# 開啟第一個終端機
./my-leader-app --kubeconfig=$HOME/.kube/config --id=instance-1
# 開啟第二個終端機
./my-leader-app --kubeconfig=$HOME/.kube/config --id=instance-2
# 開啟第三個終端機
./my-leader-app --kubeconfig=$HOME/.kube/config --id=instance-3[!NOTE] 由於整段程式碼我覺得比較長,所以我放在這邊:main.go
把整個專案跑起來後,我們會看到其中一個終端機被選舉為 Leader 並印出 “I am the leader!”,其他的則會印出 “New leader elected: instance-X”。如果我們把作為 Leader 的程式按 Ctrl+C 關閉,其他還在運行的程式就會開始競爭並選出新的 Leader。
我們也可以通過 kubectl 指令來觀察 Lease 的變化,指令如下:
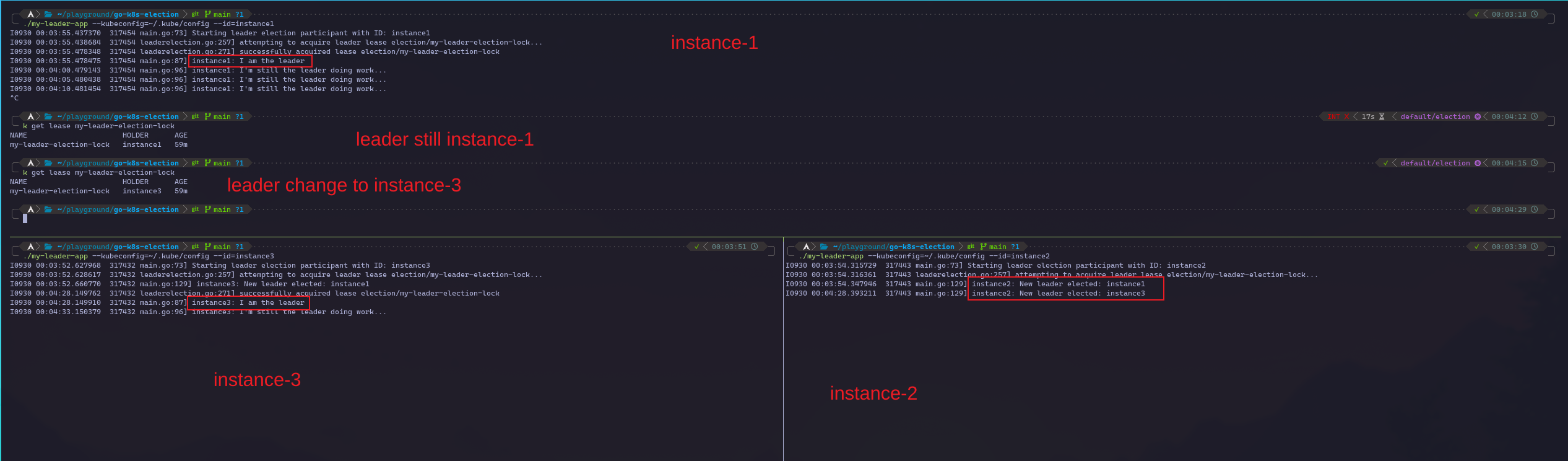
kubectl get lease my-leader-election-lock以下圖片是我自己的運行結果圖,讓我來簡單說明一下:我透過 tmux 切分出三個 terminal 視窗,模擬三個 Pod 來爭奪 Leader 的位置。
過程中可以看到,instance-1 首先取得了 Leader 的角色,同時 instance-2 和 instance-3 也會同步得知當前的 Leader 是 instance-1。
接著,我把作為 Leader 的 instance-1 結束,並透過指令將 K8s 的 Lease 資訊印出來,可以發現當前的 Leader 還是 instance-1,但過幾秒再看一次就會發現 Leader 變成了 instance-3,同時也能看到 instance-3 得知自己變成 Leader,instance-2 也同步得知 instance-3 變成 Leader。
結論
Kubernetes Leader Election 是一種分散式鎖的機制,用於在分散式應用程式中實現高可用性和協調性。通過 client-go 庫,開發者可以相對容易地將 Leader Election 功能集成到他們的程式中。 但有一點需要注意,就是當部署到 Kubernetes cluster 時,需要確保Pod 擁有正確的權限來操作 Leader Election 的資源 (例如 Lease 或 ConfigMap),並且每個 Pod 都使用唯一的 ID 參與整個 Election。
好啦,就是這樣啦。希望這篇文章可以幫助到正在觀看文章的你。